Introduction
Back in 2013, I saw a short video podcast where a few members of 343 Industries’ backend team were talking about their implementation of backend services for their latest release of Halo 4 game. This distributed backend system was built from ground up using an ongoing work of Microsoft Research team, after which they stress and load tested their implementation, so it can be prepared for a game release date. What I found fascinating, was the rare opportunity to learn about distributed architectures in perspective of gaming industry. In most cases, such information about software architectures stays behind closed doors, but this time it wasn’t the case. The resources continued to be available to the public and included talks at conferences as well as published research papers. Those resources became a ‘goldmine’ for any backend brat who was eager to do further learning and exploring.
Motivation
Now you might wonder why would I invest my time into this. Don’t get me wrong, I’m well aware that I probably won’t have an opportunity to work in this line of industry or similar level of systems that scale. However, the time I invested (and I still do) in learning it, helped me to better understand distributed systems in general. Today, this knowledge reflects whenever I make architectural decisions or contemplate about next integration, cloud service, deployment etc. For better decision making, knowing more is always beneficial.
Another thing that came as a surprise and further motivation, was the fact that entire endeavour of building such system involved working closely with academia. Microsoft Research, at that time, was developing an Actor model framework (called Orleans) which would allow developers to build a distributed services with ease. By the statement of the 343i team, after exploring several architectural options, they’ve came to conclusion that the Actor model and Orleans appeared to be a good fit. Combining their efforts and working together, they managed to improve and extend that framework in order to match their project needs.
Requirements
We can say with quite certainty, that 343i’s Halo Service team had a big task at hand. They had to rework their legacy backend code, so they can achieve that their system can sustain an initial load of over 11 million clients in a span of a few days period. Besides that, they have to make sure their system remains resilient and available with the load of several 100,000 requests per second.
Technical requirements
- Availability during peek times (availability)
- occurs on release dates, tournaments, weekends and holidays.
- Collecting massive amount of game stats (scale)
- during gameplays that result in XP, levels, scores etc.
- Un-interruptive gameplay (fault tolerance)
- by implementing resilient backend that during downtime doesn’t affect current play and doesn’t lose any data.
- Concurrency
- to handle large number of requests by running in parallel and to scale easily.
- Eventual consistency
- occasional latency in data consistency can be acceptable in most cases.
- Cloud native
- ease of development without much work with underlying cloud infrastructure.
Actor model and Orleans
In order to ease the complexity of handling concurrency in programs, a group of authors (Hewitt, Bishop and Steiger) came with a proposed solution, that would allow more formal way of working and designing concurrent systems. In their published research paper from 1973, they named this approach an Actor model.
Problems of handling parallelism of concurrent execution, such as running multiple threads or processes at the same time, was researched back in the 60s. Solutions like mutex and semaphores were introduced as a possible way of dealing with deadlocks and shared access to resources (memory, files etc).
Instead of overwhelming programmers with maintaining the order of large number of parallel executions, they proposed more elegant solution. In their way, such system could be decoupled into parts of isolated behaviors, called Actors, which execution would provide results that combined could form a greater common (system) state. Each actor encapsulates those three properties:
- identity - a unique identifier,
- behavior - a single-threaded handler that processes incoming events one by one,
- state - a volatile and/or durable state that is not shared with other actors.
Due to a fact that all actors are single-threaded and that their state is un-shareable, the shared resource problems of concurrency would no longer pose a threat. The only way actors could share their state, with the rest of the system, would be through immutable messages that could be sent from clients or from other actors.
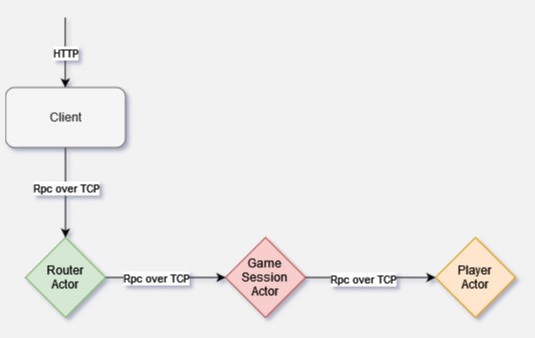
In Orleans these actors are called Grains. They are implemented as classes that describe their behavior through asynchronous methods and communicate with the other Grains via RPC calls over TCP. The Grain execution is always single-threaded. In a case of an unhandled exception, such exception will be propagated through the chain of communication until it reaches the initiator of the request.
public class GameSessionGrain : GrainBase, IGameSessionGrain
{
public Task SendMessage(long grainId)
{
IPlayerGrain playerGrain = PlayerGrainFactory.GetGrain(grainId);
string response = await playerGrain.SayHello("Hello friend!");
Console.WriteLine("Response: {0}", response);
}
}
Each Grain can be implemented as stateless or statefull service. For statefull approach, you can choose to store service state either in-memory (cache) or you can use any sort of database for durable persistance. However, during Grain’s idle time the amount of total memory reserved can be wasteful from resources standpoint. For this purpose, Orleans introduces server runtime called Silo that hosts Grains and manage their lifecycle.
Silo manages Grains lifecycle in the following way:
- If the Grain is in idle state, meaning the Grain doesn’t receive any more messages, the runtime will de-hydrate the Grain by preserving its current state (unless it’s stateless Grain) and mark it inactive while de-allocating the memory.
- In case the Grain starts receiving new messages, the runtime will re-hydrate the Grain with its previous state and continue handling the incoming events.
- During re-hydrate, there is a chance that Grain state will be stale, but in that case a Grain will refer to other actors in order achieve eventual consistency of that state.
This behavior of managing lifecycle of Grain with de-hydrate and re-hydrate actions, reveals the notion of virtual actors that continue existing even when the actual actors are inactive. Meaning, the actors are never in the fail state. For this reason, we like to refer to running Grains as virtual actor instances or activations.
Besides managing Grains lifecycles, Silo also provides a messaging subsystem that allows communication with other actors that might reside in different Silos. Each pair of Silos has a TCP connection, so each time a Grain method is called, that call will be converted and sent over TCP. Since all Grains identity and locality is transparent in entire system, the Silo’s execution will know where to send a message. Upon receiving messages a Silo will multiplex them between a set of running threads of Grains.
The cluster is a common way of organizing Silos in order to achieve fault-tolerance. In any case of Silo’s downtime, the hosted Grains activations will be re-initialized in other Silos.
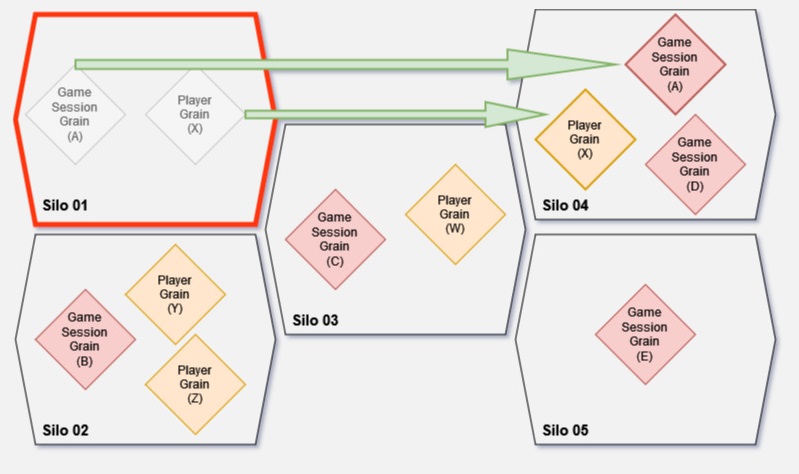
This way the system achieves a low latency and elastic scalability by resolving to multiple concurrent Grain activations.
If we reflect on the CAP theorem we can conclude following:
- Actor model doesn’t guarantee consistency
(C)due to its asynchronous nature by design. However, most of the business needs can rely on eventual consistency. - Actor model can provide high level of availability
(A)with elastic scalability and fault-tolerance. - System state is partitioned
(P)between different actors’ states.
High level architecture
Each Xbox game console is present on the dedicated network of Xbox Live. In order to play, each console has to be authenticated on that network. Also, each game title is required to provide dedicated gateways registered on Xbox Live which are than used to proxy the game requests to title’s backend services.
Incoming requests from clients like Xboxes, PCs and companion apps (Halo Waypoint and mobile apps) will than land to front facing services that provide Http Rest API.
In regards to middleware and data tier architecture, their design leveraged on the use of Orleans Silo cluster and Azure cloud hosting. In this case, each Silo instance would correspond to one node (i.e a VM or a container on Azure cloud). For a use of message queueing and persistance, they relied on the cloud services such as Service Bus and Azure Storage.
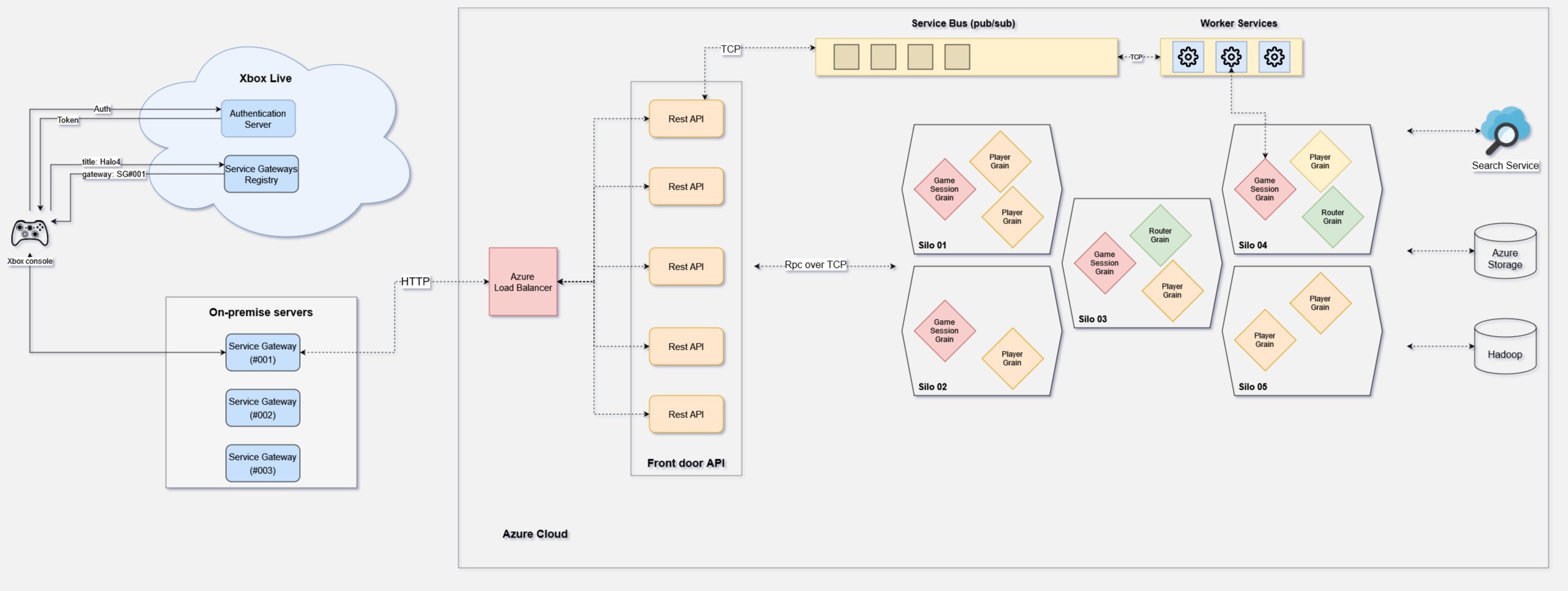
Halo services
The middle-tier workers represent the core logic of the entire system. Within this level several services were implemented:
- Presence service
- Once the game is started, this service will receive heartbeat messages from the console that will define the players presence in the game. It will also allow other clients on the network (the player’s friends) to be notified of the current status of the player and the games he/she is currently playing.
- Statistics service
- This service has responsibility of collecting statistic data for each player and gameplay ever played. These game stats can be quite large and can include vast of information such as: challenges progress, XP, total kills, total deaths, number of body and head shots, armor damage, weapons used, healing packs collected, wins and loses.
- Title Files service
- In case you want to place and send messages to different players, this service is used for publishing messages of the day, release information, matchmaking list etc.
- Cheat Detection
- Any case of forbidden behavior, can be resolved with different bans. This service would prevent cheaters of running an unsigned code on Xbox or muting toxic players in chats/microphone.
- User Generated Content
- As many games these days do, this service will also allow players to make custom maps and upload them to the game servers. Such custom maps can later be played in different gameplays.
As a developer who implements these services, your effort is channeled towards implementing Grains and occasionally Front door API. In order to demonstrate this more closely we will look into implementations of Presence and Statistics service.
Presence service
The Presence service implements three types of Grains:
- Router Grain
- Game Session Grain
- Player Grain
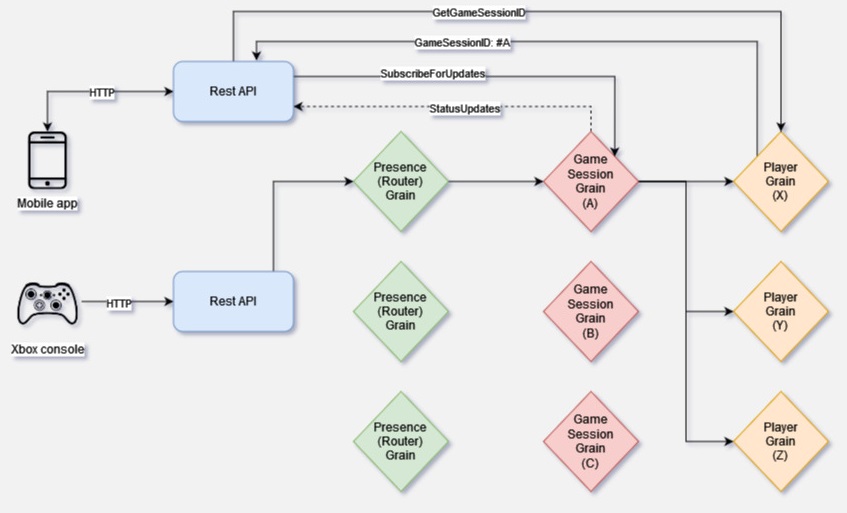
Each console sends periodically heartbeat messages with game updates to the Presence service. Once received, the Router decompresses the heartbeat and extracts GameSessionID and PlayerID. After routing the message to correct Game Session Grain the game update is saved. Such session state can contain list of players that are in game, current score, map name etc. The heartbeats are never saved on the consoles, however in the case of failure and rejoining the game, the next heartbeat from the console will restore the previous game session. From Game Session Grain, on occasion but not on every heartbeat, these messages are sent to correct Player Actor which in return updates its own state.
Now, in case of companion apps where your friends can follow your in-game presence, these clients will first contact Player Grain and receive a current GameSessionID after which they use Orleans’ Observer to subscribe to game updates. So next time the Game Session Grain performs update the clients will be notified.
Statistics service
Within Statistics service implementation there are two types of Grains:
- Game Session Grain
- Player Grain
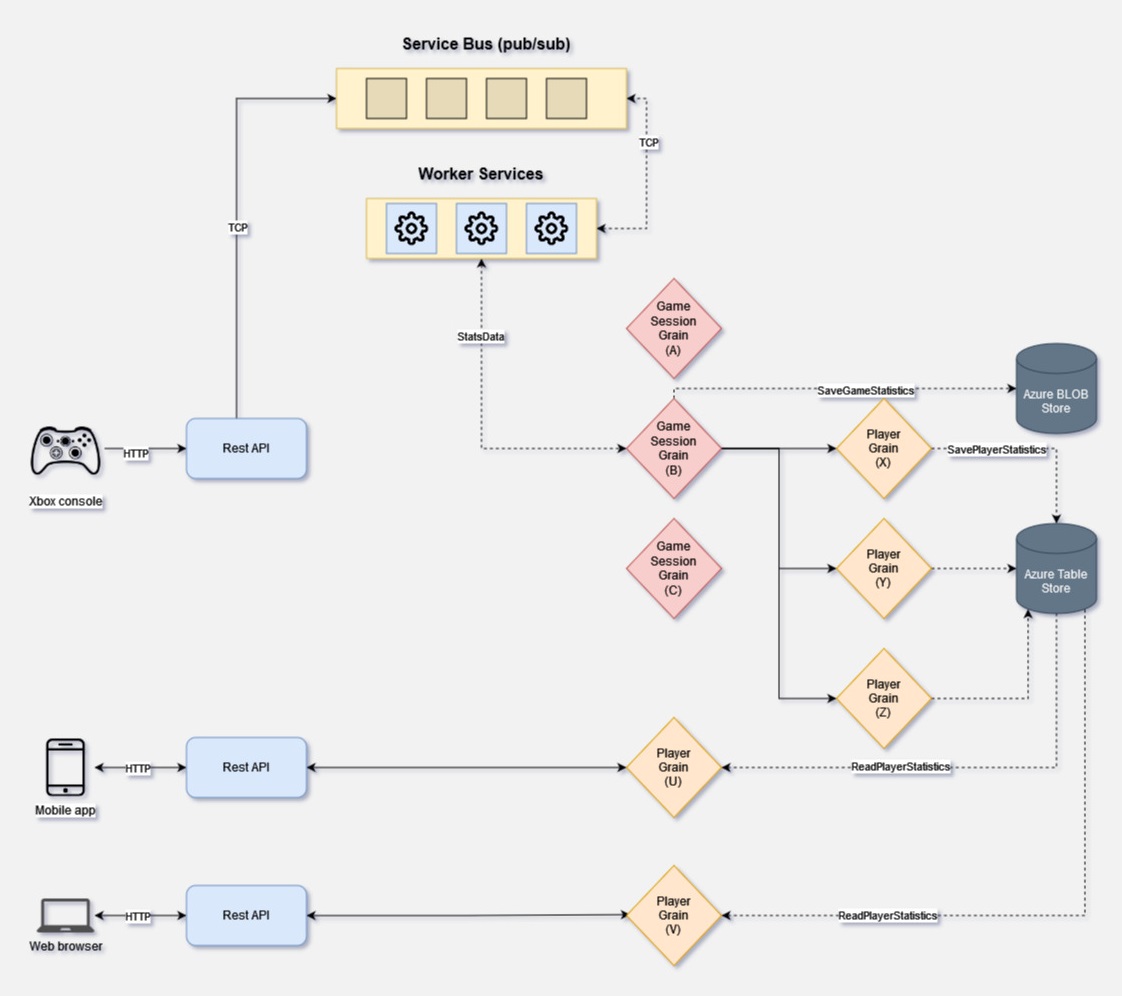
During each gameplay a statistical data are stored temporarily on the console. Each installed game has some slots reserved on a drive for these purposes. The console will periodically send partial stats during the game and full stats by the end of the game. Full stats would contain the final information about how many partial stats should be expected.
These stats are received over HTTP by the front API, and then published to Service Bus queue where there are reliably persisted. Separate set of worker processes will than pull the requests from the queue and call the correct Game Session Grain knowing its GameSessionID. Orleans performs routing by actor’s ID and if actor doesn’t exist a new Grain activation will be instantiated.
Game Session Grain will upon receive store the payload to Azure BLOB store, then it will unpack and send the relevant pieces to Player Grain. The Player Grain will process that data and store the state into Azure Table store. It is important that all operations performed by these Grains remain idempotent. That way, it is more convenient to restore the stats, in case of a failure, by simply replaying the requests.
Load testing
Sunday, 1am. Angus’ phone is ringing.
- "Hi, I'm from Azure Service Bus team. Do you own a service called *Angus Scale*?"
- "Yeah."
- "You're crushing us a little bit."
- "Ahm...Yeah...I'm scale testing."
This story has two parts. The first is the solution for a load testing that was used in testing the forth mentioned Statistics service, and the second one is how this solution caused a bit of trouble in one of Azure’s data centers.
Before describing the solution, lets quickly brief about problems of load testing. Load testing can have a lot of shapes and most of the time one thing that worked well for one system might not be the best fit for the other. More then often, engineers develop their own strategy that can work the best to their needs. And as it turns out, it was the way Halo service team proceeded with making their own plan for load testing on Statistics Service.
Another problem with load testing is a volume of data. In order to produce large volumes and preserve authenticity, developers need to randomize big sets of different information. But even then, the test data might not resemble the real world samples. Especially when it comes to game stats.
Instead of generating test data, the team decided to apply their own approach called RMP, which stands for Record, Mutate and Playback. The way load testing works is following:
- record the actual HTTP game stats requests by injecting stats recorder in front API,
- mutate the GameSessionIDs and PlayerIDs with different IDs and multiply the load by 1000x by making copies,
- playback the requests by publishing them to Service Bus as scheduled messages (will appear in queue as available at a certain point in time).
In order to reflect a real-world example, these messages were organized into sets of 100,000 messages. Each set would then be scheduled for timestamps in a range of 50ms-100ms. That way they would appear sequentially on every 50ms-100ms in a queue, representing the load stats from the 100,000 Halo players.
Now, the fun part is this accidentally caused a bit of trouble in Azure’s us-west region. What appears to be the cause was the fact that on that specific region the scheduled messages where not fully available as a feature. So, instead of receiving a sets of 100,000 messages, these queues received much more that they could handle. However, the issue was resolved and to our benefit, we learned more about this convenient approach for load testing.
Conclusion
One thing is for sure, the described solution continued to be used back in 2015 for Halo 5 release. Up to this day Azure released several gaming backends (known as PlayFab) to provide platform for developers and their titles. Also, Xbox Network (former Xbox Live) expanded its integration services in order to allow players from different networks, such as Steam and PlayStation, to play the same titles together. Since the mid of 2019, Halo Master Chief collection became available on Steam. The collection contains entire Halo franchise, so gamers could now enjoy playing all the new and past releases on their PCs. Therefore, it is safely to presume that the actual architecture upon the current time evolved and get more complex, as well as the gamers audience and load increased. It would be very interesting to see in which way legacy architecture progressed.
References
- [Github] Project Orleans
- [Talk] How Halo 4 is using Azure Service Bus (Hoop Somuah, Angus McQuarrie, Caitie McCaffrey)
- [Talk] Building Halo 4 services with Orleans by Caitie McCaffrey
- [Talk] Using Orleans to Build Halo 4’s Distributed Cloud Services in Azure by Hoop Somuah
- [Talk] Applying the Saga Pattern by Caitie McCaffrey
- [Blog] Clients are Jerks: aka How Halo 4 DoSed the Services at Launch & How We Survived by Caitie McCaffrey
- [Blog] Clarifying Orleans Messaging Guarantees by Caitie McCaffrey
- [Blog] Creating RESTful Services using Orleans by Caitie McCaffrey
- [Blog] Orleans Preview & Halo 4 by Caitie McCaffrey
- [Research paper] Orleans: Distributed Virtual Actors for Programmability and Scalability
- [Research paper] A universal modular ACTOR formalism for artificial intelligence
- [Research paper] CAP Theorem - Harvest, yield, and scalable tolerant systems
- [Research paper] CAP Theorem proof - Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services